

※ 위 책을 읽고 개념 위주로 정리한 내용임을 알립니다.
Prometheus와 Grafana가 좋은 이유
- 거의 모든 모니터링 도구와 마찬가지로, 수집 → 통합 → 시각화의 구조를 가짐
- 클라우드 서비스에 비해 비용을 절감할 수 있음
- 서비스형 모니터링 도구와 다르게 내부에서 데이터를 처리할 수 있음
Prometheus 개요
- SoundCloud 사에서 자사 서비스 모니터링을 위해 개발한 도구이며, 오픈 소스로 전환되었음
- 시계열 데이터베이스* 내장
- 자체적인 질의 페이지 말고는 시각화 기능이 없지만 그라파나와 연계하면서는 제공 가능
- 중앙 서버에서 에이전트의 데이터를 수집하는 Pull 방식을 사용하므로
쿠버네티스 환경에 설치된 에이전트를 통해 노드와 컨테이너 상태를 모두 수집해서 모니터링 가능 - 에이전트를 통해 내부 Metric*을 외부로 노출하기 때문에
사용자가 수집 대상에 접속할 수 있으면 개인 컴퓨터에서도 메트릭을 가져올 수 있음 - 자료가 많고 연계 지원도 활발하므로 직접 모니터링 시스템을 구축하려 할 때 용이하게 사용 가능
※ 시계열 데이터 베이스
- 시간을 축(키)으로 시간의 흐름에 따라 발생하는 데이터를 저장하는 데에 최적화된 데이터베이스
- 예시 : 패킷, IoT 센서 값, 이벤트 로그 등
※ Metric
- 현재 시스템의 상태를 알 수 있는 측정값
- System Metric : 파드 같은 오브젝트에서 측정되는 CPU의 메모리 사용량을 나타냄
- Service Metric : HTTP 상태 코드 같은 서비스 상태를 나타내는 지표
Grafana 개요
- Grafana Labs에서 개발한, 특정 소프트웨어에 종속되지 않은 독립적 시각화 도구
- 30가지 이상의 다양한 수집 도구 및 데이터베이스들과의 연계 지원
- 주로 시계열 데이터의 시각화에 많이 쓰이지만, 관계형 DB의 데이터를 표 형태로 시각화하는 것도 가능
- 플러그인과, 다른 유저들이 만들어둔 대시보드가 매우 활발하게 공유되고 있음
- 오픈 소스라서 사용자의 요구 사항에 맞게 수정이 가능하고 설치형과 서비스형 모두 선택 가능
Full Monitoring Pipeline
- 메트릭 데이터를 저장 공간에 따로 저장하는 방식
- 이 설계 방식을 반영한 도구가 프로메테우스
- 이 방식으로 구성한 프로메테우스는 여러 수집 대상이 공개하는
메트릭 데이터를 모아서 시계열 데이터베이스에 저장함 - 누적된 메트릭 데이터로는 쿠버네티스 인프라의 상태 변화를 파악할 수 있고,
적절한 위험 감지 및 조치를 취할 수 있음
Prometheus의 Object들
prometheus-server
- 프로메테우스의 주요 기능을 수행하는 요소
- 3가지 역할을 맡음
- 여러 대상에서 공개된 메트릭을 수집하는 수집기
- 수집한 시계열 메트릭 데이터를 저장하는 시계열 데이터베이스
- 저장된 데이터를 질의하거나 수집 대상의 상태를 확인할 수 있는 웹 UI
node-exporter
- 노드의 시스템 메트릭 정보를 HTTP로 공개하는 역할
- 설치된 노드에서 특정 파일들을 읽고, 이를 프로메테우스 서버가 수집할 수 있는
메트릭 데이터로 변환한 후 노드 익스포터에서 HTTP 서버로 공개하는 방식 - 이렇게 공개된 내용을 프로메테우스 서버에서 수집하게 됨
kube-state-metrics
- API 서버로 쿠버네티스 클러스터의 여러 메트릭 데이터 수집 후
이를 프로메테우스 서버가 수집할 수 있는 메트릭 데이터로 변환해서 공개하는 역할 - 프로메테우스가 쿠버네티스 클러스터의 여러 정보를 손쉽게 획득할 수 있도록 해줌
alertmanager
- 프로메테우스에 경보 규칙을 설정하고,
경보 이벤트 발생 시 설정된 경보 메시지를 대상에게 전달하는 기능 제공 - 프로메테우스에 설치 시 프로메테우스 서버에서 주기적으로 경보를 보낼 대상을 감시해서
시스템을 안정적으로 운영할 수 있도록 해줌
pushgateway
- 배치와 스케줄 작업 시 수행되는 일회성 작업들의 상태를 저장하고 모아서
프로메테우스가 주기적으로 가져갈 수 있도록 제공함 - 일반적으로 짧은 시간 동안 실행되고 종료되는 배치성 프로그램의 메트릭 저장이나
외부망에서 접근할 수 없는 내부 시스템의 메트릭을 프록시 형태로 제공하는 용도로 사용
Prometheus 활용하기
Helm으로 Prometheus 설치하기
- 프로메테우스는 젠킨스처럼 헬름으로 쉽게 설치 가능
- 다만 젠킨스 설치 때와 마찬가지로 NFS 디렉토리를 만들고,
NFS 디렉토리를 쿠버네티스 환경에서 사용할 수 있도록 PV와 PVC로 구성해야 함
Prometheus의 Web UI
Graph
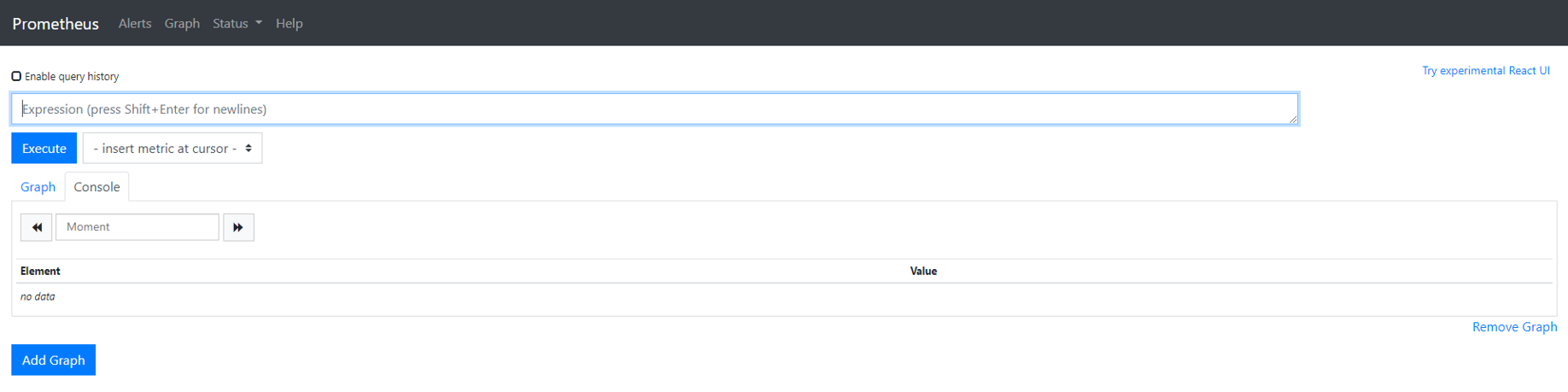
- 프로메테우스 접속 시 가장 먼저 만나게 되는 메뉴 (그만큼 중요한 내용을 처리하는 페이지!)
- Enable query history
- 프로메테우스가 적재한 메트릭 데이터를 조회할 수 있는 표현식을 입력하는 곳
- 사용하는 표현식은 PromQL(Prometheus Query Language) 이라는 프로메테우스의 쿼리 언어
- 시계열 데이터베이스를 RDBMS처럼 쿼리문을 작성해서 효과적으로 필요한 메트릭 추출
- Graph
- PromQL을 통해 메트릭 데이터를 확인할 때, 시각적으로 표현해주는 옵션
- 데이터를 시각화한 영역형 또는 막대형 차트를 보여줌
- Console
- PromQL로 추출된 데이터를 보여주는 기본 옵션
- 표 형식으로 표현하기 때문에 개별 데이터 파악에 용이
- Add Graph
- 그래프 추가가 아닌, 쿼리 입력기를 하나 더 추가해서 다른 메트릭을 확인할 수 있게 하는 버튼
- Remove Graph
- 현재 쿼리 입력기 제거
Alerts
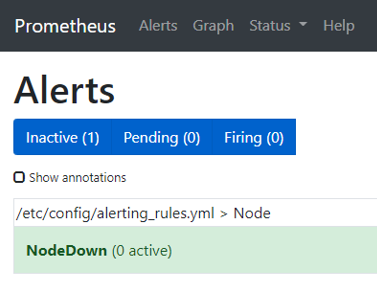
- 현재 프로메테우스 서버에 등록된 경보 규칙과 경보 발생 여부 확인 가능
Status
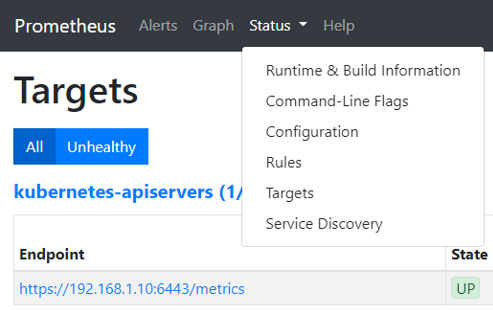
- Runtime & Build Information : 런타임 관련 정보, 버전을 나타내는 빌드 정보 등을 확인 가능
- Command-Line Flags : 프로메테우스 서버가 실행될 때 인자로 입력받았던 값을 보여줌
- Rules : 프로메테우스 서버에 등록된 다양한 규칙 확인
- Targets : 프로메테우스 서버가 수집해오는 대상의 상태 확인
- Service Discovery : 프로메테우스 서버가 서비스 디스커버리 방식으로 수집한 대상들에 대한 정보
Service Discovery
정보를 수집하려면 일반적으로 에이전트를 설정해야 하지만, 쿠버네티스가 에이전트에
추가에 입력하지 않고도 자동으로 메트릭 정보를 수집할 수 있는 것은 서비스 디스커버리 덕분
작동 순서
- 프로메테우스 서버는 ConfigMap에 기록된 내용을 바탕으로 대상을 읽어옴
- 읽어온 대상에 대한 메트릭을 가져오기 위해 API 서버에 정보 요청
- 요청을 통해 알아온 경로를 통해 메트릭 데이터 수집
크게 2가지 방법을 사용
- cAdvisor : 쿠버네티스 API 서버에 직접 연결된 경로를 통해 메트릭 수집
- Agent : API가 알려준 경로를 통해 메트릭 수집
Grafana 활용하기
Helm으로 Grafana 설치하기
- 젠킨스, 프로메테우스와 마찬가지로 헬름을 이용해서 간단하게 설치 가능
Grafana의 메뉴

Search
- 사용자가 만든 대시보드를 태그 또는 이름으로 검색
Create
- 새로운 대시보드 구성 및 다른 사람의 대시보드를 추가하는 기능
- 대시보드를 분류해서 관리하는 폴더도 여기서 설정 가능
Dashboards
- 만들어진 여러 대시보드를 연결
- Playlists : 한 화면에 슬라이드 쇼처럼 확인
- Snapshots : 특정 시간의 대시보드 화면을 캡쳐 및 공유
Explore
- 데이터 소스를 선택해서 여러 표현식을 확인
- PromQL 표현식 테스트 가능
Alerting
- 그라파나에서 경보를 보내기 위한 채널과 경보 규칙을 설정하는 메뉴
Configuration
- 대시보드 구성을 설정하는 하위 메뉴들
Server Admin
- 새로운 사용자 추가, 애플리케이션 상태와 설정값 확인
- 주로 그라파나 관리자가 사용하는 메뉴
Dashboard settings
- Home을 설정할 수 있는 메뉴
- 처음에는 홈 화면을 설정하지만 대시보드가 추가되면 추가된 대시보드를 설정할 수 있음
Cycle view mode
- 대시보드에 표시된 내용만 집중해서 볼 수 있는 모드로 변경하는 메뉴
- 처음 한 번 누르면 왼쪽 메뉴가 사라지는 TV 모드
- 한 번 더 누르면 위쪽 메뉴가 사라지는 kiosk 모드
- 변환된 모드에서 esc 를 누르면 다시 일반 모드
Node Metric data 시각화하기
- 그라파나는 대시보드를 만들고 그 안에 패널이라는 구성 요소를 추가하는 방식으로 메트릭 데이터를 시각화함
- 시각화 방식 : Graph, Stat, Gauge, Bar Gauge, Table, Text, Heatmap,
Alert list, Dashboard list, News, Logs, Plugin list
Pod Metric data 시각화하기
- 노드 메트릭의 시각화와 동일하지만 파드가 여러 네임스페이스에 존재하므로
사용자가 원하는 네임스페이스에 속한 파드만 확인할 수 있도록 해야 함 - 그러기 위해서 변수를 선언하고, 변수로 원하는 내용만 선별해서 대시보드에서 확인하도록 하는 작업 필요
Alertmanager로 이상 신호 감지하고 알려주기
- 그라파나에도 얼럿 메뉴가 있지만 오직 시각화 그래프에만 존재하기에 프로메테우스의 얼럿매니저가 더 나음
- Prometheus > Alerts
- alert : 경보 메시지를 대표하는 이름
- expr : PromQL 표현식으로 경보 규칙을 설정해서 true 값이 나오면 경보 발생
- for : 문제 지속 시간
- annotations : 하위 항목에 필요한 전달 메시지를 주석으로 기록
- description : 사용자 임의 지정 변수로 필요한 경보 내용 작성
내가 만든 대시보드 공유하기
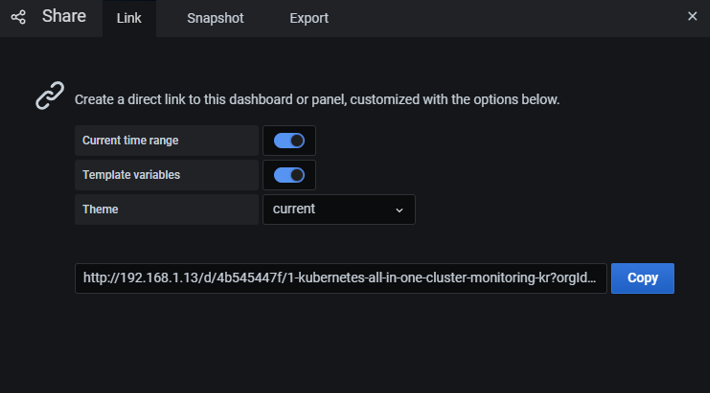
Link
- 다른 사용자가 대시보드에 접속할 수 있는 링크 주소의 옵션
Snapshot
- 대시보드의 현재 상태를 저장해서 대시보드에 접근할 수 없는 곳에서 확인 가능하도록 설정
Export
- 대시보드를 JSON 파일로 내보냄
- JSON 파일은 그라파나 대시보드 저장소에 올리거나 다른 사용자에게 직접 전달 가능
- Export for sharing externally : 다른 사람이 만든 대시보드를 가져올 때 데이터 소스 선택
다른 사람이 만든 대시보드 가져오기
https://grafana.com > Dashboards 탭 이용하기
'Infrastructure' 카테고리의 다른 글
| Kubernetes와 친해지기 (0) | 2022.04.28 |
|---|---|
| Jenkins (0) | 2022.04.27 |
| Docker (0) | 2022.04.26 |
| Kubernetes (0) | 2022.04.25 |
| 컨테이너 인프라 환경 (0) | 2022.04.25 |