

※ 위 책을 읽고 개념 위주로 정리한 내용임을 알립니다.
Kubernetes는 무엇인가?
- 표면적으로는 Container 관리 도구이지만, 실제로는 Container Orchestration을 위한 솔루션
- Orchestration : 복잡한 단계를 관리하고 요소들의 유기적인 관계를 미리 정의해서
손쉽게 사용하도록 서비스를 제공하는 것을 뜻함 - 다수의 컨테이너를 유기적으로 연결하고 실행하고 종료할 뿐만 아니라
상태를 추적하고 보존하는 등 컨테이너를 안정적으로 사용할 수 있도록 만들어 줌
- Orchestration : 복잡한 단계를 관리하고 요소들의 유기적인 관계를 미리 정의해서
※ k8s의 의미
: 'kubernetes'에서 앞의 k와 뒤의 s만 두고 나머지 8자는 축약했다는 뜻
: 참고로 kubernetes는 그리스 어로 도선사나 조타수를 뜻함
Kubernetes 구성 방법 3가지
1. 퍼블릭 클라우드 업체에서 제공하는 관리형 쿠버네티스 사용
- EKS(Amazon Elastic Kubernetes Service), AKS(Azure Kubernetes Service),
GKE(Google Kubernetes Engine) 등을 사용 - 구성이 이미 다 갖춰져 있으며, 마스터 노드를 클라우드 업체에서 관리함
2. 설치형 쿠버네티스 사용
- 수세의 Rancher, 레드햇의 OpenShift 사용
- 유료라 쉽게 접근하기 어려움
3. 구성형 쿠버네티스 사용
- 시스템에 쿠버네티스 클러스터를 자동으로 구성해주는 솔루션 사용
- kubeadm, kops, KRIB, kubespray 등이 있으며, kubeadm이 가장 널리 알려져 있음
- kubeadm은 사용자가 변경하기 수월하고, 온프레미스와 클라우드를 모두 지원하며, 배우기도 쉬움
파드 배포를 중심으로 쿠버네티스 구성 요소 살펴보기 (실습 환경)
- kubectl, kubelet, API 서버, 캘리코, etcd, 컨트롤러 매니저, 스케줄러, kube-proxy, 컨테이너 런타임, 파드 등
- 구성 요소 확인 명령어 : kubectl get pods --all-namespaces
관리자나 개발자가 파드를 배포하는 시점
마스터 노드
0. kubectl
- 쿠버네티스 클러스터에 명령을 내리는 역할
- 바로 실행되는 명령 형태인 binary로 배포되기 때문에 마스터 노드에 있을 필요는 없음
- 하지만 통상적으로 API 서버와 통신하므로 실습에서는 API 서버가 위치한 마스터 노드에 구성한 것
1. API 서버
- 쿠버네티스 클러스터의 중심 역할을 하는 통로
- 주로 상태 값을 저장하는 etcd와 통신
- 다른 요소들 또한 API 서버를 중심에 두고 통신
2. etcd
- 구성 요소들의 상태 값이 모두 저장되는 곳
- etcd 외의 다른 구성 요소는 상태 값을 관리하지 않음
- 그러므로 etcd의 정보만 백업되어 있다면 긴급 상황에서도 쿠버네티스 클러스터 복구 가능
- key-value 저장소이므로, 복제해서 여러 곳에 저장해두면 하나의 etcd에서 장애가 나도 시스템 가용성 확보 가능
- etcd는 리눅스 구성 정보를 갖고 있는 etc와 distributed(퍼뜨렸다)의 합성어
3. 컨트롤러 매니저
- 쿠버네티스 클러스터의 오브젝트 상태를 관리
- 예를 들어 워커 노드에서 통신이 되지 않는 경우, 상태 체크와 복구는 컨트롤러 매니저의 노드 컨트롤러에서 이루어짐
- 다른 예로 레플리카셋 컨트롤러는 레플리카셋에 요청받은 파드 개수대로 파드 생성
- 이와 같이 다양한 상태 값을 관리하는 주체들이 컨트롤러 매니저에 소속되어 각자의 역할 수행
4. 스케줄러
- 노드의 상태와 자원, 레이블, 요구 조건 등을 고려해서 파드를 어떤 워커 노드에 생성할 것인지 결정하고 할당
- 파드를 조건에 맞는 워커 노드에 지정하고, 파드가 워커 노드에 해당하는 일정을 관리하는 관리자 역할 담당
워커 노드
5. kubelet
- PodSpec을 받아서 컨테이너 런타임으로 전달
- 파드 안의 컨테이너들이 정상적으로 작동하는지 모니터링
6. CRI(Container Runtime Interface)
- 파드를 이루는 컨테이너의 실행을 담당
- 파드 안에서 다양한 종류의 컨테이너가 문제 없이 작동하게 만드는 표준 인터페이스
7. Pod
- 1개 이상의 컨테이너로 단일 목적의 일을 하기 위해서 모인 단위
- 웹 서버 역할을 할 수도 있고, 로그나 데이터를 분석할 수도 있음
- 중요한 점 : 파드는 언제나 죽을 수 있는 존재
- 이것이 쿠버네티스를 처음 배울 때 가장 이해하기 어려운 부분
- 가상 머신은 언제라도 죽을 수 있다고 가정하고 디자인하지 않음
- 파드는 언제라도 죽을 수 있다고 가정하고 설계되었기 때문에 쿠버네티스는 여러 대안을 디자인했음
선택 가능한 구성 요소
11. 네트워크 플러그인
- 쿠버네티스 클러스터의 통신을 위한 것
- 일반적으로 CNI로 구성함
- 주로 사용하는 CNI : Calico, Flannel, Cilium, Kube-router, Romana, WeaveNet, Canal
12. CoreDNS
- 클라우드 네이티브 컴퓨팅 재단에서 보증하는 프로젝트로, 빠르고 유연한 DNS 서버
- 쿠버네티스 클러스터에서 도메인 이름을 이용해서 통신하는 데에 사용함
- 실무에서 쿠버네티스 클러스터를 구성할 때 IP보다는 도메인 네임을 관리해주는 CoreDNS를 사용하는 것이 일반적
사용자가 배포된 파드에 접속하는 시점
1. kube-proxy
- 파드가 위치한 노드에 파드가 통신할 수 있도록 네트워크 설정
- 실제 통신은 br_netfilter와 iptables로 관리
2. Pod
- 이미 배포된 파드에 접속해서 필요한 내용을 전달받음
- 이때 사용자는 파드가 어느 워커 노드에 위치하는지 신경 쓰지 않아도 됨
파드의 생명주기로 쿠버네티스 구성 요소 살펴보기 (실습 환경)
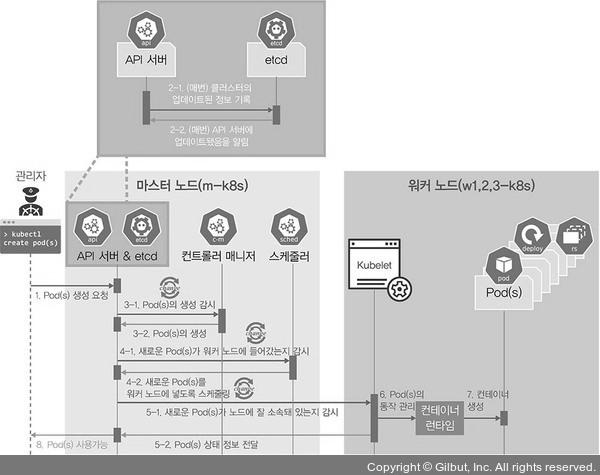
- kubectl을 통해 API 서버에 파드 생성 요청
- API 서버에 전달된 내용이 있으면 etcd에 전달된 내용을 모두 기록해서 클러스터의 상태 값을 최신으로 유지
- 파드 생성 요청을 컨트롤러 매니저가 인지하면 파드 생성 후 상태를 API 서버에 전달
- 스케줄러는 API 서버에 파드가 생성되었다는 정보 인지 → 워커 노드를 정하고 해당 워커 노드에 파드를 띄움
- kubelet으로 API 서버의 정보대로 지정한 워커 노드에 파드가 속해 있는지를 확인
- kubelet에서 컨테이너 런타임으로 파드 생성 요청
- 파드 생성
- 파드가 가용 상태가 됨
⭐ 쿠버네티스는 작업을 순서대로 진행하는 workflow 구조가 아닌 declarative 시스템 구조를 가지고 있음
- 각 요소가 desired status를 선언하면 current status와 맞는지 점검하며 맞추려고 시도하는 구조
- 추구하는 상태를 API 서버에 선언하면 다른 요소들이 API 서버와 현재 상태를 비교하며 상태를 맞춤
- API는 현 상태 값을 가지며, 이를 보존하기 위해 etcd 필요
- 그런데 실습 상에서 워커 노드는 워크플로우 구조에 따라 설계되었음
- 쿠버네티스가 kubelet과 컨테이너 런타임을 통해 파드 생성 및 제거를 하는 구조이기 때문
Kubernetes 기본 사용법
Pod 생성 방법
- 쿠버네티스를 사용한다는 것은 결국 사용자에게 효과적으로 파드를 제공한다는 뜻
- kube run 명령어로 파드를 쉽게 생성할 수 있음
- 예시 : kubectl run nginx-pod --image=nginx
- kubectl create 명령어는 deployment를 추가해서 실행
- 예시 : kubectl create deployment dpy-nginx --image=nginx
- run은 단일 파드 1개만 생성 / create deployment는 Deployment 내에 파드 생성
- 비유를 들자면, 초코파이 1개를 그냥 생성한 것과 초코파이 1개를 초코파이 상자에 생성한 것의 차이
- 최근에는 대부분 create로 파드를 생성하지만 단순 테스트 목적이라면 run도 사용해볼 수 있을 것
Object
Pod
- 쿠버네티스에서 실행되는 최소 단위
- 독립적인 공간과 사용 가능한 IP를 가짐
- 1개의 파드는 1개 이상의 컨테이너를 갖고 있기 때문에 여러 기능을 묶어 하나의 목적을 위해 사용 가능
- 범용적으로 대부분 1개의 파드에 1개의 컨테이너를 적용함
Namespaces
- 쿠버네티스 클러스터에 사용되는 리소스들을 구분해서 관리하는 그룹
- 예를 들어 실습에서는 3가지 네임스페이스를 사용함
- default : 특별히 지정하지 않으면 기본적으로 할당
- kube-system : 쿠버네티스 시스템에서 사용됨
- metallb-system : 온프레미스에서 쿠버네티스 클러스터 내부 접속을 돕는 컨테이너들
Volume
- 파드 생성 시 파드에서 사용할 수 있는 디렉토리 제공
- 기본적으로 파드는 영속되는 개념이 아니기 때문에 제공되는 디렉토리 또한 임시
- 파드가 사라지더라도 저장과 보존이 가능한 디렉토리를 볼륨 오브젝트를 통해 생성하고 사용
Service
- 파드는 클러스터 내에서 유동적이기에 접속 정보가 고정될 수 없음
- 따라서 파드 접속의 안정적인 유지를 위해 서비스를 이용해서 내/외부 연결
- 새 파드가 생성될 때 부여되는 새로운 IP를 기존 기능과 연결
- 쿠버네티스 외부에서 내부를 신경 쓰지 않아도 내부 환경을 논리적으로 연결해줌
- 기존 인프라의 로드밸런서, 게이트웨이와 비슷한 역할
Deployment
- 기본 오브젝트 만으로도 쿠버네티스를 사용할 수 있지만 기능들을 조합하고 더 효율적으로 작동하도록 해줌
- 파드에 기반을 두고 있으며 레플리카셋 오브젝트를 합쳐 놓은 형태
- 이외에도 DaemonSet, ConfigMap, ReplicaSet, PV, PVC, StatefulSet 등이 있음
ReplicaSet
- 다수의 파드를 하나씩 생성하는 비효율적인 작업을 해결하기 위한 오브젝트
- 예를 들어 파드를 3개 만들겠다고 레플리카셋에 선언하면
컨트롤러 매니저와 스케줄러가 워커 노드에 파드 3개를 만들도록 선언하는 방식 - 그러나 레플리카셋은 파드 수를 보장하는 기능만 제공하기에 Deployment 사용을 권장함
Kubernetes 연결을 담당하는 Service
NodePort
- 가장 간단하게 연결하는 service
- 노드포트 서비스를 설정하면 모든 워커 노드의 특정 포트를 열고 여기로 오는 모든 요청을 노드포트 서비스로 전달
- 이후 노드포트 서비스는 해당 업무를 처리할 수 있는 파드로 요청을 전달함
- 포트를 중복 사용할 수 없기에 1개의 노드포트에 1개의 디플로이먼트만 적용
Ingress
- 사용 목적별로 연결하는 service
- 노드포트와 달리 여러 개의 디플로이먼트를 다룰 때 사용
- 고유한 주소를 제공해서 사용 목적에 따른 응답 제공 가능
- 트래픽에 대한 L4/L7 로드밸런서와 보안 인증서를 처리하는 기능 제공
- 사용하려면 인그레스 컨트롤러 필요
- 인그레스 컨트롤러는 파드와 직접 통신할 수 없고, 노드포트 또는 로드밸런서와 연동되어야 함
- 인그레스 컨트롤러의 궁극적인 목적 : 사용자가 접속하려는 경로에 따라 다른 결과값을 제공하는 것
LoadBalancer
- 클라우드에서 쉽게 구성 가능한 service
- 앞선 방식에 비해서 간단하게 파드를 외부에 노출하고 부하를 분산할 수 있도록 해줌
- 사용하려면 로드밸런서를 이미 구현해 둔 서비스 업체의 도움을 받아서 쿠버네티스 클러스터 외부에 구현해야 함
MetalLB
- 온프레미스에서 로드밸런서를 제공하는 service
- bare metal(운영 체제가 설치되지 않은 하드웨어)에서도 로드밸런서를 사용하도록 고안된 프로젝트
- 기존의 L2 네트워크(ARP/NDP)와 L3 네트워크(BGP)로 로드밸런서 구현
- MetalLB 컨트롤러는 protocol을 정의하고 EXTERNAL-IP를 부여해서 관리
- MetalLB Speaker는 정해진 작동 방식(L2/L3)에 따라 경로를 만들도록 네트워크 정보를 수집해서 파드 경로 제공
HPA(Horizontal Pod Autoscaler)
- 부하에 따라 자동으로 파드 수를 조절하는 service
- 자원을 요청할 때 Metrics-Server를 통해 계측값을 전달받음
알아두면 쓸모 있는 Kubernetes Object
DaemonSet
- Deployment의 replicas가 노드 수 만큼 정해져 있는 형태
- 노드 1개당 파드 1개만을 생성
- 노드를 관리하는 파드라면 가장 효율적인 오브젝트
ConfigMap
- 이름 그대로 설정을 목적으로 사용하는 오브젝트
PV(PersistentVolume) / PVC(PersistentVolumeClaim)
- 파드에서 생성한 내용을 유지해야 할 때 공유된 볼륨으로부터 공통된 설정을 가져오도록 설계하기 위한 오브젝트
- PV : 지속적으로 사용 가능한 볼륨
- PVC : 지속적으로 사용 가능한 볼륨 요청
- PVC를 사용하려면 PV로 볼륨을 선언해야 함
- 간단하게 PV는 볼륨을 사용할 수 있게 준비하는 단계 / PVC는 준비된 볼륨에서 일정 공간을 할당받는 것
StatefulSet
- 파드가 만들어지는 이름과 순서를 예측해야 할 때 사용하는 오브젝트
- volumeClaimTemplates 기능을 사용해서 PVC 자동 생성 가능
- 각 파드가 순서대로 생성되기 때문에 고정된 이름, 볼륨, 설정 등을 가질 수 있음
- 이름 그대로 '이전 상태를 기억하는 세트'
- expose 명령어는 지원되지 않으므로 로드밸런서 서비스를 작성 및 실행해야 함
- IP를 가지지 않는 Headless 서비스로 노출 가능 (쿠버네티스 클러스터 내에서 통신 가능)
'Infrastructure' 카테고리의 다른 글
| Kubernetes와 친해지기 (0) | 2022.04.28 |
|---|---|
| Prometheus & Grafana (0) | 2022.04.28 |
| Jenkins (0) | 2022.04.27 |
| Docker (0) | 2022.04.26 |
| 컨테이너 인프라 환경 (0) | 2022.04.25 |