

※ 위 책에서 부록을 제외한 5개의 챕터들 중 1 챕터를 정리한 내용임을 알립니다.
※ 상당히 방대한 분량의 책이다 보니, 리와인드 하기에 좋은 액기스 내용들을 간추리고 간추려서 정리했음을 알립니다.
0. 첫 개발 스터디를 시작하다!
10월 11일부터, 드디어 내 인생 처음으로 개발 관련 스터디에 참여해 볼 수 있는 기회를 얻었다.
소재가 되어준 책이 『HTTP 완벽 가이드』라는 점도 좋았다.
여기까지 성장해 오면서 스스로가 기본기를 등한시해왔다는 생각이 드는 만큼,
모든 개발자가 알아야 할 정도로 중요하게 여겨지는 HTTP 기본기를 다지고 싶다는 욕심이 생겼다.
1. HTTP의 역할
Q. 그래서 HTTP가 뭔데?
- HyperText Transfer Protocol, 말 뜻 그대로 표현하자면,
HTML과 같은 하이퍼미디어 문서를 전송하기 위한 애플리케이션 레이어의 프로토콜 - 쉽게 표현하자면, 전 세계의 웹 서버로부터 대량의 정보를 빠르고, 간편하고, 정확하게 브라우저로 옮겨주는
인터넷 상의 배달부! - 신뢰성 있는 데이터 전송 프로토콜을 사용하기 때문에, 데이터가 어디에서 오더라도 손상되거나 꼬이는 일이 없음!
=> 그렇기 때문에 개발자는 인터넷의 데이터 전송에 대한 걱정 없이 애플리케이션 고유의 기능 구현에 집중할 수 있음
2. 미디어 타입
HTTP는 웹에서 전송되는 객체 각각에게 MIME 타입이라는 데이터 포맷 라벨을 붙임
- 이 MIME 타입을 통해서 인터넷 상의 수천 가지 데이터 타입을 다룰 수 있는 것!
MIME (Multipurpose Internet Mail Extensions, 다목적 인터넷 메일 확장)
- 이름에서도 알 수 있듯이, 본래에는 전자메일 시스템에서 서로 다른 메시지들을 다루기 위해 만들어졌음
- 이 타입이 전자메일 시스템에서 워낙 잘 동작했기 때문에,
HTTP에서도 멀티미디어 컨텐츠를 기술하고 라벨링하기 위해서 채택한 것
HTTP에서의 MIME 타입 활용도
- 웹 서버는 모든 HTTP 객체 데이터에게 MIME 타입을 붙임
- 웹 브라우저는 서버로부터 객체를 받을 때 이 MIME 타입을 확인함으로써 본인이 다룰 수 있는지 여부를 판단함
MIME 타입 예시
- text/plain, text/html, text/css, text/javascript
- image/gif, image/png, image/jpeg, image/bmp, image/webp
- application/pkcs12, application/vnd.mspowerpoint, application/xml, application/pdf
3. HTTP 트랜잭션
HTTP 트랜잭션의 기본
- HTTP 트랜잭션은 요청 명령과 응답 결과로 구성되어 있음
- 트랜잭션을 위한 상호작용은 HTTP 메시지라 불리는 정형화된 데이터를 덩어리를 통해서 이루어짐
HTTP 메소드
- HTTP는 HTTP 메소드라 불리는 여러 종류의 요청 명령을 지원함
- 모든 HTTP 요청 메시지는 1개의 메소드를 가짐
- HTTP 메소드는 서버에게 어떤 동작이 취해져야 하는지 알려주는 역할을 수행함
- 대표적인 5개의 메소드 : GET, POST, PUT, DELETE, HEAD
HTTP 상태 코드
- 모든 HTTP 응답 메시지는 상태 코드와 함께 반환됨
- 상태 코드는 클라이언트의 요청이 어떻게 되었는지 알려주는 세 자리의 숫자
- 대표적인 3개의 상태 코드 : 200(OK), 302(Temoporarily Moved), 404(Not Found)
웹 페이지는 여러 객체로 이루어질 수 있다
- 웹 애플리케이션은 보통 하나의 작업을 위해 여러 번의 HTTP 트랜잭션을 수행함
- 만약 시각적 볼거리가 풍성한 웹 페이지를 보고자 한다면 대량의 HTTP가 발생할 수 있는 것
- 웹 페이지는 보통 하나의 리소스가 아닌, 리소스의 모음이라고 할 수 있음
4. HTTP 프로토콜 버전
HTTP/0.9
- 1991년의 HTTP 프로토타입
- 심각한 디자인 결함이 다수 있으며, 구식 클라이언트하고만 함께 사용할 수 있음
- GET 메소드만을 지원 / 멀티미디어 컨텐츠에 대한 MIME 타입, HTTP 헤더, 버전 번호 미지원
HTTP/1.0
- 본격적으로 널리 쓰이기 시작한 버전
- HTTP 헤더, 추가 HTTP 메소드, 멀티미디어 객체 처리 추가
- 시각적으로 매력적인 웹 페이지와 상호작용하는 폼을 실현해냈음
- World Wide Web 을 대세로 만들게 된 계기라고 할 수 있음
- 아직은 잘 정의된 명세라고 보기엔 어려운 시점이었지만,
학술적으로 급성장하던 시기에 만들어진, 잘 동작하는 용례들의 모음이라고 할 수는 있음
HTTP/1.0+
- 1990년대 중반, WWW가 급격 팽창하고 상업적 성공을 거두면서, 발 빠르게 HTTP에 기능들이 추가되었음
- 오래 지속되는 keep-alive 커넥션, 가상 호스팅, 프록시 연결 지원
- 비공식적으로 개발된 기능들이긴 하지만, 사실상의 표준으로서 HTTP에 추가되었음
- 규격 외적으로 확장된 버전이기 때문에 HTTP/1.0+ 라고 불리게 된 것
HTTP/2.0
- HTTP/1.1 성능 문제를 개선하기 위해 Google의 SPDY 프로토콜 기반으로 설계가 진행 중인 프로토콜
HTTP/3
- 스터디원 분을 통해 알게 된 것인데, TCP 대신 UDP 프로토콜을 사용하는 차세대 프로토콜로서,
현재 Google에서 이미 사용 중인 것으로 알고 있음
5. 웹의 구성 요소
Proxy
- 웹 보안, 애플리케이션 통합, 성능 최적화를 위해 기여하는 중요한 구성 요소
- 클라이언트와 서버 사이에서 클라이언트의 모든 HTTP 요청을 받아서 특정 작업을 수행한 뒤, 서버에 전달
- 주로 보안을 위해서 사용되고 있음
Cache
- 웹 캐시 및 캐시 프락시는 자신을 거쳐 가는 문서들 중 자주 찾는 문서들의 사본을 저장해두는 HTTP 프록시 서버
- 클라이언트가 자주 찾는 문서를 다시 요청했을 때, 캐시가 갖고 있는 사본을 받을 수 있도록 해줌
- 이에 따라 클라이언트는 멀리 떨어져 있는 웹 서버보다 근처의 캐시에서 훨씬 더 빠르게 문서를 내려받을 수 있게 됨
- HTTP는 캐시를 효율적으로 동작하게 하고, 캐시된 컨텐츠를 최신 버전으로 유지하면서,
동시에 프라이버시까지도 보호할 수 있도록 많은 기능들을 정의해 두고 있음
Gateway
- 다른 서버들을 위한 중개자로 동작하는 특별한 서버
- 주로 HTTP 트래픽을 다른 프로토콜로 변환하기 위해서 사용됨
- 언제나 자신이 직접 리소스를 가지고 있는 것 마냥 진짜 서버처럼 요청을 다루므로,
클라이언트는 자신이 게이트웨이와 통신하고 있는지를 알아채기 어려움 - 예시) HTTP/FTP 게이트웨이는 FTP URI에 대한 HTTP 요청을 받아들인 뒤,
FTP 프로토콜을 이용해서 문서를 가져옴
Tunnel
- 두 커넥션 사이에서 raw 데이터를 열어보지 않고 그대로 전해주는 HTTP 애플리케이션
- 주로 HTTP 데이터를 하나 이상의 HTTP 연결을 통해 그대로 전송하기 위해서 사용됨
- 예시) 암호화된 SSL 트래픽을 HTTP 커넥션으로 전송함으로써 웹 트래픽만 허용하는 사내 방화벽을 통과시킬 때
+ 스터디 모임에서 이야기할 때, 사실 이 부분이 용도가 뚜렷하게 보이지 않아서 헷갈렸는데,
우선은 사내 보안 측면으로 많이 활용되고 있다는 정도로 이해하고 있습니다.
혹시나 더욱 다양한 활용 예시가 있으시다면 부담 없이 공유 부탁드립니다. 🙏
Agent
- 사용자를 위해 HTTP 요청을 대신 만들어주는 클라이언트 프로그램
- 웹 요청을 만들어 주는 애플리케이션이라면 뭐든지 다 HTTP 에이전트
- HTTP 에이전트에는 웹 브라우저 말고도 다른 종류의 것들이 많음
- 예시) 사람의 통제 없이도 스스로 웹을 돌아다니며 HTTP 트랜잭션을 일으키고 컨텐츠를 받아오는 자동화 에이전트
6. TCP 커넥션에 대해
- 전 세계의 모든 HTTP 통신은 패킷 교환 네트워크 프로토콜들의 계층화된 집합인 TCP/IP를 통해 이루어짐
- 일단 커넥션이 맺어지고 나면,
주고받는 메시지들은 손실되거나, 손상되거나, 순서가 뒤바뀌거나 하지 않고 안전하게 전달됨
신뢰할 수 있는 데이터 전송 통로, TCP
- 사실 HTTP 커넥션은 몇몇 사용 규칙을 빼버리면 TCP 커넥션이나 다름 없게 되어버림
- 그러므로 신속하고 정확하게 데이터를 보내고자 한다면, TCP의 기초적인 내용들을 알아둬야 함
- TCP는 HTTP에게 신뢰할 수 있을 만한 통신 방식을 제공해줌
- TCP 커넥션 상에서 각 byte들은 순서에 맞게 정확히 전달됨
TCP 스트림은 세그먼트로 나뉘어서, IP 패킷을 통해 전송된다

- TCP는 IP 패킷이라 불리는 작은 조각을 통해 데이터를 전송함
- HTTP는 메시지를 전송할 때, 연결되어 있는 TCP 커넥션을 통해서 메시지의 내용을 순서대로 전송함
- TCP/IP 소프트웨어에 의해서 처리되는 과정은 HTTP 프로그래머에게 보이지 않음
- 각 TCP 세그먼트는 하나의 IP 주소에서 다른 IP 주소로 IP 패킷에 담겨서 전달되며, 다음 요소들을 포함하고 있음
- IP 패킷 헤더: 발신지 IP 주소, 목적지 IP 주소, 크기, 기타 플래그
- TCP 세그먼트 헤더: TCP 포트 번호, TCP 제어 플래그, 데이터 순서 무결성 검사를 위한 숫자 값
- TCP 데이터 조각
TCP 커넥션 유지하기
- 컴퓨터는 항상 TCP 커넥션을 여러 개 가지고 있으며, TCP는 포트 번호를 통해서 커넥션을 유지하고 있음
- IP 주소는 해당 컴퓨터에 연결되고, 포트 번호는 해당 애플리케이션으로 연결되는 것
- TCP 커넥션은 발신지 IP 주소, 발신지 포트, 수신지 IP 주소, 수신지 포트 4가지 값으로 식별됨
- 이 4개의 값들을 통해 중복되지 않는 유일값의 커넥션을 생성할 수 있음
7. TCP 소켓 프로그래밍
- 운영체제는 TCP 커넥션의 생성과 관련된 여러 기능들을 제공함
- 소켓 API는 HTTP 프로그래머에게 TCP와 IP의 세부사항들을 감춰주고 주요 인터페이스를 보여줌
- 유닉스 운영체제용으로 먼저 개발되었는데, 지금은 대부분의 운영체제 및 프로그래밍 언어에서도 사용 가능
| 소켓 API | 설명 |
| s = socket(<parameters>) | 연결되지 않은 익명의 새 소켓 생성 |
| bind(s, <local IP:port>) | 소켓에 로컬 포트 번호 및 인터페이스 할당 |
| connect(s, <remote IP:port>) | 로컬 소켓과 원격 호스트 및 포트 사이에 TCP 커넥션 생성 |
| listen(s, ...) | 로컬 소켓에서의 커넥션 허용 |
| s2 = accept(s) | 로컬 포트에 커넥션이 맺어지기를 기다림 |
| n = read(s, buffer, n) | 소켓으로부터 버퍼에 n byte 읽기 시도 |
| n = write(s, buffer, n) | 소켓으로부터 버퍼에 n byte 쓰기 시도 |
| close(s) | TCP 커넥션 완전 끊기 |
| shutdown(s, <side>) | TCP 커넥션 입출력만 닫음 |
| getsockopt(s, ...) | 내부 소켓 설정 옵션값 얻기 |
| setsockopt(s, ...) | 내부 소켓 설정 옵션값 변경 |
- 소켓 API를 사용하면 TCP endpoint 데이터 구조를 생성하고,
원격 서버의 endpoint에 생성된 endpoint를 연결해서 데이터 스트림을 읽고 쓸 수 있음 - TCP API는 기본적인 네트워크 프로토콜의 핸드셰이킹, TCP 데이터 스트림,
IP 패킷 간 분할 및 재조립에 대한 모든 세부사항을 외부로부터 숨겨줌
+ 이번 장은 추후 웹 소켓 관련 프로그래밍을 할 때 보탬이 되어줄 수 있을 것 같아서 정리해보았습니다. 😎
8. TCP 성능 지연 요소들
HTTP 트랜잭션 지연
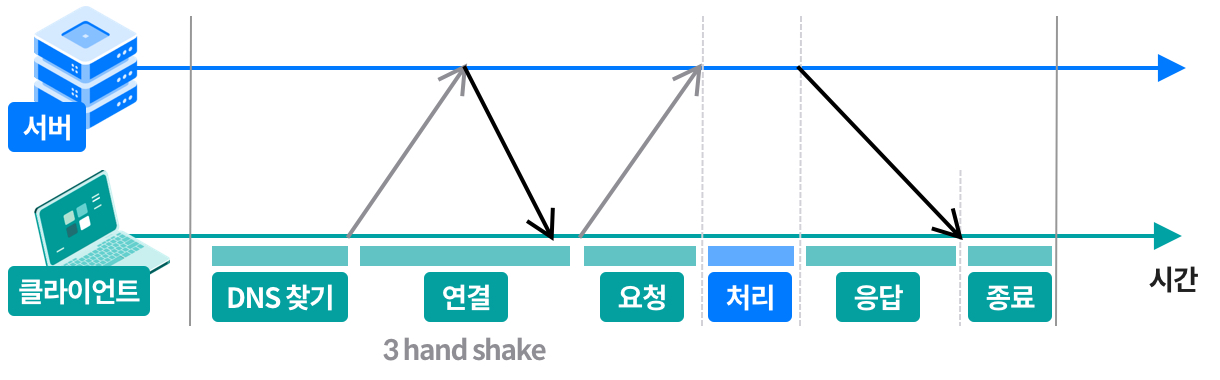
- 트랜잭션을 처리하는 시간 자체는 사실 TCP 커넥션 설정, 요청 전송, 응답 전송 시간에 비하면 상당히 짧음
- 지나치게 많은 데이터를 처리하는 경우가 아니라면, 대부분의 HTTP 지연은 TCP 네트워크 때문에 발생하는 것!
HTTP 트랜잭션이 지연되는 여러 원인들
- 클라이언트는 URI를 통해서 웹 서버의 IP 주소와 포트 번호를 알아내야 함
- 클라이언트는 TCP 커넥션 요청을 서버에 보낸 후에 서버의 커넥션 허가 응답을 기다려야만 함
- 커넥션이 맺어진 후 TCP 파이프를 통해 요청을 전달하고 처리하는 과정에서의 시간 소모가 있음
- 웹 서버에서도 HTTP 응답을 만들고 보내주는 데에 시간 소모가 있음
TCP 커넥션 핸드셰이크 지연
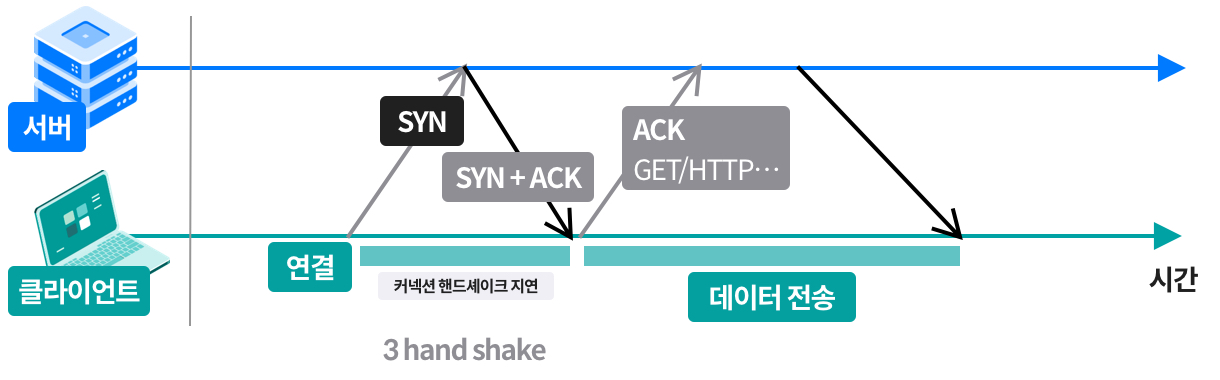
TCP 커넥션이 핸드셰이크를 하는 순서
- 클라이언트는 새 TCP 커넥션 생성을 위해 TCP 패킷(보통 40~60 byte)을 서버에게 보냄
패킷은 '커넥션 생성' 요청이라는 뜻의 SYN 이라는 특별한 플래그를 가짐 - 서버는 커넥션으로부터 몇 가지 커넥션 매개변수를 산출하고,
커넥션 요청이 받아들여졌다는 의미로 SYN 과 ACK 플래그를 포함한 TCP 패킷을 클라이언트에게 보냄 - 클라이언트는 커넥션이 잘 맺어졌음을 알리기 위해 서버에 다시 확인응답 신호를 보냄
HTTP의 입장에서 볼 때는...
- HTTP 프로그래머는 이 패킷들을 볼 수 없고, TCP 소프트웨어가 보이지 않게 관리함
- 크기가 적당한 정도의 HTTP 트랜잭션이라면, 트랜잭션 시간의 50% 이상을 TCP 구성에 사용하게 됨
- TCP의 ACP 패킷은 많은 요청 메시지와 응답 메시지를 하나의 IP 패킷에 담을 수 있음 (수백 byte 정도의 사이즈)
확인응답 지연
TCP 세그먼트는 데이터 전송 보장을 위해 순번과 데이터 무결성 체크섬을 가짐
- 각 세그먼트 수신자는 세그먼트를 온전히 받았을 때 확인응답 패킷을 송신자에게 반환
- 송신자는 특정 시간 이내에 확인응답 메시지를 받지 못하면 오류가 있다고 간주하고 데이터를 재전송
확인응답은 그 크기가 작기 때문에 모아서 보내려고 같은 방향으로 가는 데이터 패킷들을 piggyback(편승) 시킴
- 네트워크를 효율적으로 사용하기 위한 방편
- '확인응답 지연' 알고리듬은 많은 TCP 스택이 편승될 수 있도록 구현되어 있음
- 우선 송출할 확인응답을 잠시 버퍼에 저장해두고, 편승시킬 수 있는 송출 데이터 패킷을 찾아냄
그리고 만약 일정 시간 내에 송출 데이터 패킷을 찾아내지 못하면 그냥 별도 패킷을 만들어서 전송함
한계점
- 요청과 응답 2가지 형식으로만 이루어지는 HTTP 동작 방식은 편승의 기회를 감소시킴
- 편승할 다른 패킷들도 딱히 없는데 모아서 갈려고 하니까 괜한 시간 지연이 발생함
=> 운영체제에 따라 다르기는 하지만, 확인응답 지연 관련 기능을 수정하거나 비활성화할 수는 있음
TCP slow start
- TCP는 처음에 커넥션 최대 속도를 제한하다가, 데이터가 성공적으로 전송되었을 때 속도 제한을 높여줌
- 인터넷의 급작스러운 부하와 혼잡을 방지하기 위한 용도
- 1개의 패킷부터 전송하고 확인응답을 받고, 2개의 패킷을 전송하고 확인응답을 받고,
또 각각의 패킷에 대한 확인응답을 받으면 총 4개의 패킷을 전송할 수 있게 되는 셈 - 이러한 과정을 opening the congestion window (혼잡의 창문을 여는 것) 라고도 불림
Nagle 알고리듬과 TCP_NODELAY
Nagle 알고리듬
- Nagle 알고리듬은 네트워크 효율을 위해서, 패킷을 전송하기 전에 많은 양의 TCP 데이터를 한 덩어리로 합침
- 세그먼트에 최대 크기를 채우지 못했을 경우 데이터를 전송하지 않음
- 크기가 작은 HTTP 메시지는 앞으로 생길지 안 생길지조차 모르는 추가 데이터를 하염없이 기다리게 되므로,
HTTP 성능과 관련해서 심각한 문제를 발생시킬 수도 있음
TCP_NODELAY
- HTTP 스택에 TCP_NODELAY 파라미터 값을 설정함으로써 Nagle 알고리듬을 비활성화하기도 함
9. HTTP 커넥션 관리 방법들
순차 커넥션
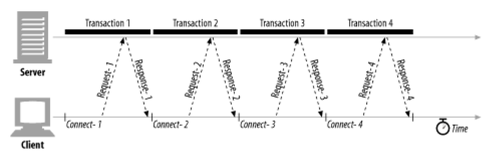
- 요청이 있을 때마다 새로운 커넥션을 맺고 끊는 것을 반복하는 일반적인 방법
- 커넥션 관리가 제대로 이루어지지 않는다면 TCP 성능이 매우 안 좋아질 수 있음
- 매 커넥션마다 맺고 끊는 과정이 있을 것이고, 느린 시작 지연도 덤으로 먹고 들어가야 함
병렬 커넥션
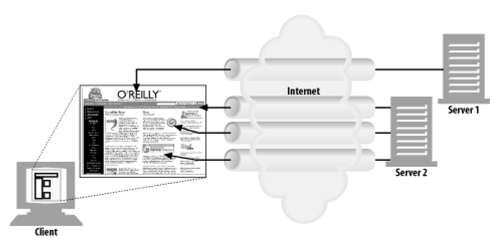
- 여러 개의 TCP 커넥션을 활용해서 동시에 요청하는 방법
- 커넥션 대역폭 제한 및 커넥션이 놀고 있는 시간들을 잘 활용하면 여러 객체들을 빠르게 내려받을 수 있음
- 하지만 네트워크 대역폭이 좁다면 대부분의 시간을 데이터 전송에만 쓰게 될 것
- 다수의 커넥션은 메모리 소모가 심해서 브라우저들은 6~8개 정도의 병렬 커넥션만을 허용함
지속 커넥션
- 보통 서버에 HTTP 요청을 하기 시작한 애플리케이션은 해당 서버에 또다시 요청을 하게 됨
- 이러한 속성을 site locality 라고 부름
- HTTP/1.1에서는 트랜잭션 처리 완료 후에도 커넥션을 유지해서 재사용할 수 있게 함
- 하지만 계속 연결된 상태로 유지되어 있는 지속 커넥션이 쌓이지 않도록 관리를 잘 해주어야 함
- Connection: Keep-Alive 헤더를 활용해서 커넥션을 지속할 것인지 결정할 수 있음
- 오늘날 많은 웹 애플리케이션들은 적은 수의 '병렬' 커넥션을 '지속적으로' 유지함
파이프라인 커넥션
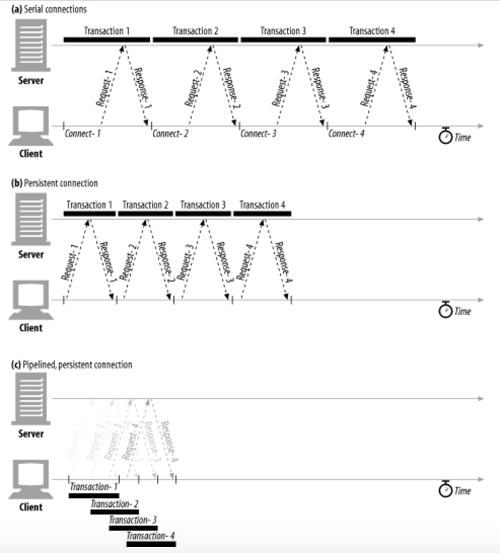
- HTTP/1.1은 지속 커넥션을 통해서 요청을 파이프라이닝 할 수도 있음
- 이는 Keep-Alive 커넥션의 성능을 더욱 높여줌
- 요청이 서버에 전달된 시점에 큐에 있는 다음 요청을 이어서 전송함
- 꼭 지속 커넥션인지를 확인한 후에 파이프라인을 이어야 함
- 커넥션이 끊어지더라도 파이프라인에 남아 있는 요청들은 다시 보낼 준비가 되어 있어야 함
- 비멱등 요청들은 반복되면 어떤 요청들이 처리되었는지 알 수 없게 되므로 사용하면 안됨