
※ 본문은 김영한 선생님의 인프런 '모든 개발자를 위한 HTTP 웹 기본 지식' 강의를 듣고 정리한 내용임을 알립니다.
▶ HTTP의 활용도
: HyperText Transfer Protocol
→ 지금은 HTTP 메시지에 모든 것을 전송
=> HTML, TEXT, IMAGE, 음성, 영상, 파일, JSON 및 XML, 서버 간에 데이터를 주고 받을 때
▶ HTTP 버전
→ TCP : HTTP/1.1, HTTP/2
→ UDP : HTTP/3
=> 현재 HTTP/1.1을 주로 사용하지만 HTTP/2, HTTP/3의 사용도 점점 증가하고 있다.
▶ HTTP 특징
: 클라이언트 서버 구조
: 무상태 프로토콜(Stateless), 비연결성
: HTTP 메시지를 통해서 통신
: 단순하고 확장 가능
▶ 클라이언트 서버 구조
: Request / Response 구조
→ 클라이언트는 서버에 요청을 보내고 응답을 대기
→ 서버가 요청에 대한 결과를 만들어서 응답
=> 중요한 포인트는 클라이언트와 서버를 개념적으로 분리했다는 점!
비즈니스 로직이나 데이터는 서버에 남기고 클라이언트는 UI, 사용성에 집중
클라이언트와 서버가 독립적으로 성장할 수 있게 됨
▶ Stateless (무상태 프로토콜)
- 서버가 클라이언트의 상태를 보존하지 않음
- 장점 : 서버 확장성 높음 (스케일 아웃)
- 단점 : 클라이언트가 추가 데이터를 전송해야 함
=> 모든 것을 무상태로 설계할 수는 없다. (ex.로그인 유지)
=> 상태 유지(Stateful)는 최소한만 사용하는 것이 좋다.
※ 서버 개발자들이 어려워 하는 업무 : 같은 시간에 딱 맞추어 발생하는 대용량 트래픽 (선착순 이벤트, 학과 수업 등록)
→ 최대한 Stateless를 활용해서 설계하자!
▶ 비연결성 (Connectionless)
- HTTP는 기본적으로 연결을 유지하지 않는 모델
- 일반적으로 초 단위 이하의 빠른 속도로 응답
- 1시간 동안 수천 명이 서비스를 사용해도 실제 서버에서 동시에 처리하는 요청은 수십 개 이하로 매우 적음
- 서버 자원을 매우 효율적으로 사용할 수 있음
- 한계1 : TCP/IP 연결을 새로 맺어야 함 (3 way handshake 시간 추가)
- 한계2 : 웹 브라우저로 사이트를 요청하면 HTML 뿐만 아니라 자바스크립트, CSS, 추가 이미지 등 수많은 자원을 함께 다운로드
- 극복 : 지금은 HTTP 지속 연결(Persistent Connection)로 문제 해결, HTTP/2, HTTP/3에서 더 많은 최적화


▶ HTTP 메시지

1. 시작 라인 - 요청 메시지
: start-line = request-line / status-line
: request-line = method SP(공백) request-target SP HTTP-version CRLF(엔터)
: ① HTTP 메소드 ② 요청 대상 ③ HTTP Version
→ HTTP 메소드
: 서버가 수행해야 할 동작 지정
: GET, POST, PUT, DELETE 등
→ 요청 대상
: absolute-path[?query] (절대경로[?쿼리])
: 절대경로="/" 로 시작하는 경로
=> ex) GET /search?q=hello&hl=ko HTTP/1.1
2. 시작라인 - 응답 메시지
: start-line = request-line / status-line
: status-line = HTTP-version SP status-code SP reason-phrase CRLF
=> HTTP 상태 코드 : 요청 성공이나 실패를 나타냄
=> 이유 문구 : 사람이 이해할 수 있는 짧은 상태 코드 설명 글
ex) HTTP/1.1 200 OK
3. HTTP 헤더

: HTTP 전송에 필요한 모든 부가정보
ex) 메시지 바디 내용, 메시지 바디 크기, 압축, 인증, 요청 클라이언트(브라우저), 서버 애플리케이션, 캐시 관리 정보 등
4. HTTP 메시지 바디

: 실제 전송할 데이터
ex) HTML 문서, 이미지, 영상, JSON 등 byte로 표현할 수 있는 모든 데이터
=> HTTP는 단순하다. 크게 성공하는 표준 기술은 단순하면서도 확장 가능한 기술임을 알 수 있다.
▶ HTTP 메소드 종류
1. GET
- 리소스 조회
- 서버에 전달하고 싶은 데이터는 쿼리를 통해서 전달
- 메시지 바디를 사용해서 데이터를 전달할 수 있지만, 지원하지 않는 곳이 많아서 권장하지 않음
2. POST
- 요청 데이터 처리
- 메시지 바디를 통해 서버로 요청 데이터 전달
- 서버는 요청 데이터를 처리 (메시지 바디를 통해 들어온 데이터를 처리하는 모든 기능을 수행)
- 주로 전달된 데이터는 신규 리소스 등록, 프로세스 처리에 사용
★ 리소스 URI에 POST 요청이 오면 데이터를 어떻게 처리할지 리소스마다 따로 정해야 함 (정해진 것이 없음)
=> POST의 사용방식
→ 새 리소스 등록
→ 요청 데이터 처리
: 단순히 데이터를 생성하거나 변경하는 것을 넘어서 프로세스를 처리해야 하는 경우
└> ex) 주문에서 결제 완료 -> 배달 시작 -> 배달 완료 (POST /orders/{orderId}/start-delivery (컨트롤 URI))
→ 다른 메소드로 처리하기 애매한 경우
ex) JSON으로 조회 데이터를 넘겨야 하는데 GET 메소드를 사용하기 어려운 경우
: 애매하면 POST를 사용하자
3. PUT
- 리소스를 대체 (없으면 생성, 있으면 덮어쓰는 방식)
- 클라이언트가 리소스의 구체적인 경로를 알고 URI 지정 (POST와의 큰 차이점!)
★ PUT은 리소스를 수정하는 것이 아닌, 갈아치우는 것
4. PATCH
- PUT의 단점을 보완하여 리소스 부분 변경 가능
5. DELETE
- 리소스 제거
▶ HTTP 메소드 속성

1. 안전 (Safe)
: 호출해도 리소스를 변경하지 않는다.
Q. 계속 호출해서 로그가 쌓여서 장애가 발생한다면?
A. 해당 리소스만 고려. 그런 부분까지 고려하지 않음
2. 멱등 (Idempotent)
: 몇 번을 호출하든 결과가 똑같다.
→ GET : 몇 번을 조회하든 같은 결과를 조회한다.
→ PUT : 결과를 대체한다. 같은 요청을 여러번하면 최종 결과는 똑같다.
→ DELETE : 결과를 삭제한다. 같은 요청을 여러번해도 삭제된 결과는 똑같다.
→ 만약 결제를 두번 한다면 중복해서 결제될 수 있어서 멱등이 아니다.
=> 활용 : 자동 복구 메커니즘, 서버가 정상 응답을 못주었을 때 같은 요청을 다시 해도 되는지에 대한 판단 근거
※ 멱등은 외부 요인으로 중간에 리소스가 변경되는 것 까지는 고려하지 않는다.
3. 캐시가능 (Cacheable)
: 응답 결과 리소스를 캐시해서 사용해도 되는가?
: GET, HEAD, POST, PATCH는 캐시 가능하지만 실제로는 GET, HEAD 정도만 캐시로 사용
▶ 클라이언트에서 서버로 데이터 전송
※ 데이터 전달 방식은 크게 2가지
1. 쿼리 파라미터를 통한 데이터 전송
→ GET
→ 주로 정렬 필터 (검색어)
2. 메시지 바디를 통한 데이터 전송
→ POST, PUT, PATCH
→ 회원 가입, 상품 주문, 리소스 변경
▶ POST와 PUT의 차이
: POST는 서버가 새로 등록된 리소스 URI를 생성하고 관리해준다. (컬렉션)
ex) 응답 메시지 : HTTP/1.1 201 Created Location: /members/100
: PUT은 클라이언트가 리소스 URI를 알고 등록해야 한다. (스토어)
ex) 요청 메시지 : PUT /files/star.jpg
=> 실무에서는 POST를 주로 사용
※ 참고하면 좋은 URI 설계 개념
1. 문서(document)
- 단일 개념 (파일 하나, 객체 인스턴스, 데이터베이스 row)
- ex) /members/100, /files/star.jpg
2. 컬렉션(collection)
- 서버가 관리하는 리소스 디렉토리
- 서버가 리소스의 URI를 생성하고 관리
- ex) /members
3. 스토어(store)
- 클라이언트가 관리하는 자원 저장소
- 클라이언트가 리소스의 URI를 알고 관리
- ex) /files
4. 컨트롤러(controller), 컨트롤 URI
- 문서, 컬렉션, 스토어로 해결하기 어려운 추가 프로세스 실행
- 동사를 직접 사용하면 알아보기 쉬움
- ex) /members/{id}/delete
=> 정답은 아니고 좋은 Practice로 이해하자.
▶ 상태 코드
: 클라이언트가 보낸 요청의 처리 상태를 응답에서 알려주는 기능
- 1xx (Informational) : 요청이 수신되어 처리중
- 2xx (Successful) : 요청 정상 처리
- 3xx (Redirection) : 요청을 완료하려면 추가 행동 필요
- 4xx (Client Error) : 클라이언트 오류, 잘못된 문법 등으로 서버가 요청을 수행할 수 없음
- 5xx (Server Error) : 서버 오류, 서버가 정상 요청을 처리하지 못함
▶ 2xx (Successful)
- 200 OK : 요청 성공
- 201 Created : 요청에 성공해서 새로운 리소스가 생성됨
- 202 Accepted : 요청이 접수되었으나 처리가 완료되지 않았음 (요청 접수 후 일정시간 뒤에 처리하는 배치 처리에 사용)
- 204 No Content : 서버가 요청을 성공적으로 수행했지만, 응답 페이로드 본문에 보낼 데이터가 없음
▶ 3xx (Redirection)
※ Redirection : 웹 브라우저는 3xx 응답의 결과에 Location 헤더가 있으면 Location 위치로 자동 이동
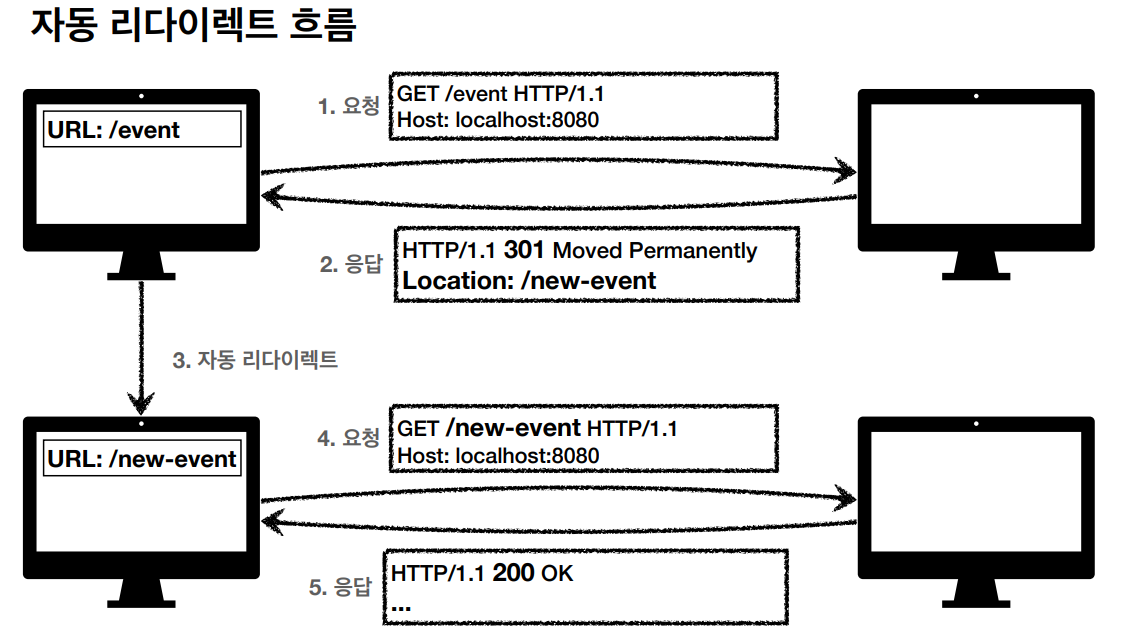
◈ 리다이렉션의 종류
1. 영구 리다이렉션
→ 특정 리소스의 URI가 영구적으로 이동
→ 원래의 URL 사용 X
→ 301 Moved Permanently : 리다이렉트 시 요청 메소드가 GET으로 변하고 본문이 제거될 수 있음
→ 308 Permanent Redirect : 301과 기능은 같지만 리다이렉트 시 요청 메소드와 본문 유지 (POST로 보내면 POST 유지 가능)
=> 실무에서는 거의 사용하지 않는 방법들
/* 제 블로그는 방문자가 적은 편이지만 유독 308 Permanent Redirect 키워드를
검색해서 들어오신 분이 많기에 이렇게 주석을 남깁니다.
저 또한 개발 경력이 없기 때문에 확신할 수 없지만 추측건대, 308 Permanent Redirect는
한 때 이벤트 관련 페이지였다가 이벤트 종료 후 해당 페이지 URI를 더 이상 사용하지 않게 되었거나
혹은 홈페이지 URI 자체를 옮겼거나 홈페이지 자체가 없어진 경우인 것 같습니다.
저는 308 Permanent Redirect를 직접 본 적이 없기 때문에 이 정도로 추측할 수 밖에 없군요...
아무쪼록 우연이라도 제 블로그를 방문해주신 분들에게 조금이나마 도움이 되었으면 합니다. */
2. 일시 리다이렉션
→ 리소스의 URI가 일시적으로 변경
→ 검색 엔진 등에서 URL을 변경하면 안됨
→ 302 Found : 리다이렉트 시 요청 메소드가 GET으로 변하고 본문이 제거될 수 있음(MAY)
→ 307 Temporary Redirect : 302와 기능은 같지만 리다이렉트 시 요청 메소드와 본문 유지 (요청 메소드 변경 MUST NOT)
→ 303 See Other : 302와 기능은 같음, 리다이렉트 시 요청 메소드가 GET으로 변경(MUST)
=> 307, 303을 권장하지만 많은 애플리케이션이 302를 사용하고 있으며, 302를 사용해도 큰 문제는 없다.
★ PRG (Post / Redirect / Get)
→ POST로 주문 후에 웹 브라우저를 새로고침한다면? 중복 주문이 발생할 수 있다.
→ POST로 주문 후에 주문 결과 화면을 GET 메소드로 리다이렉트
→ 새로고침해도 결과 화면을 GET으로 조회하게 됨

3. 특수 리다이렉션
→ 결과 대신 캐시를 사용
→ 클라이언트에게 리소스가 수정되지 않았음을 알려줌
→ 클라이언트는 로컬 PC에 저장된 캐시를 재사용 (캐시로 리다이렉트)
→ 메시지 바디를 포함하면 안됨 (로컬 캐시를 사용해야 하므로)
→ 조건부 GET, HEAD 요청 시 사용
→ 응답 시 304 Not Modified 사용
- 300 Multiple Choices
- 301 Moved Permanently
- 302 Found
- 303 See Other
- 304 Not Modified
- 307 Temporary Redirect
- 308 Permanent Redirect
▶ 4xx (Client Error)
: 오류의 원인이 클라이언트에게 있음
: 클라이언트의 요청에 잘못된 문법 등으로 서버가 요청을 수행할 수 없음
★ 4xx와 5xx의 차이 : 4xx는 똑같은 재시도가 무조건 실패, 5xx는 성공할 가능성이 있음
- 400 Bad Request : 클라이언트가 잘못된 요청을 해서 서버가 요청을 처리할 수 없음
- 401 Unauthorized : 클라이언트가 해당 리소스에 대한 인증이 필요함 (WWW-Authenticate 헤더로 방법 설명)
- 403 Forbidden : 서버가 요청을 이해했지만 승인을 거부함 (인증 자격 증명은 있지만 접근 권한 불충분)
- 404 Not Found : 요청 리소스를 찾을 수 없음, 또는 클라이언트가 해당 리소스를 숨기고 싶을 때
▶ 5xx (Server Error)
- 500 Internal Server Error : 서버 내부 문제로 오류 발생, 애매하면 500 에러
- 503 Service Unavailable : 일시적인 과부하 또는 예정된 작업으로 인해 서비스 이용 불가 (Retry-After 헤더 활용)
▶ HTTP 헤더

1. Content-Type : 표현 데이터의 형식
→ 미디어 타입, 문자 인코딩
→ text/html; charset=utf-8
→ application/json
→ image/png
2. Content-Encoding : 표현 데이터 인코딩
→ 표현 데이터를 압축하기 위해 사용
→ 데이터를 전달하는 곳에서 압축 후 인코딩 헤더 추가
→ 데이터를 읽는 쪽에서 인코딩 헤더의 정보로 압축 해제
→ gzip / deflate / identity
3. Content-Language : 표현 데이터의 자연 언어
→ ko / en / en-US
4. Content-Length : 표현 데이터의 길이
→ 바이트 단위
→ Transfer-Encoding(전송 코딩)을 사용하면 Content-Length를 사용하면 안됨
▶ HTTP 헤더의 컨텐츠 협상
: 클라이언트가 선호하는 표현 요청
- Accept : 클라이언트가 선호하는 미디어 타입 전달
- Accept-Charset : 클라이언트가 선호하는 문자 인코딩
- Accept-Encoding : 클라이언트가 선호하는 압축 인코딩
- Accept-Language : 클라이언트가 선호하는 자연 언어
※ 협상 헤더는 요청 시에만 사용
+ 협상과 우선순위
- Quality Values(q) 값 사용
- 0~1, 클수록 높은 우선순위
- 생략하면 1
- Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
▶ HTTP 전송 방식
- 단순 전송 (Content-Length)
- 압축 전송 (Content-Encoding)
- 분할 전송 (Transfer-Encoding)
- 범위 전송 (Range, Content-Range)
▶ HTTP 헤더 일반 정보
- Form : 유저 에이전트의 이메일 정보 / 일반적으로 잘 사용되지 않음 / 검색 엔진 같은 곳에서 주로 사용 (요청)
- Referer : 이전 웹 페이지 주소 / 유입 경로를 분석할 때 많이 사용 (요청)
- User-Agent : 유저 에이전트 애플리케이션 정보 / 어떤 브라우저에서 장애가 발생하는지 파악 가능 (요청)
- Server : 요청을 처리하는 오리진 서버의 소프트웨어 정보 (응답)
- Date : 메시지가 생성된 날짜 (응답)
▶ HTTP 헤더 특별 정보
- Host : 요청한 호스트 정보(도메인) / 필수값 / 하나의 서버가 여러 도메인을 처리할 때를 위한 대책 (요청)
- Location : 페이지 리다이렉션 (응답)
- Allow : 허용 가능한 HTTP 메소드 / 405(Method Not Allowed)에서 응답에 포함 / 거의 사용 X (응답)
- Retry-After : 유저 에이전트가 다음 요청을 하기까지 기다려야 하는 시간 (응답)
▶ HTTP 인증과 관련된 헤더
- Authorization : 클라이언트 인증 정보를 서버에 전달 (요청)
- WWW-Authenticate : 리소스 접근 시 필요한 인증 방법 정의 / 401(Unauthorized) 응답과 함께 사용 (응답)
▶ 쿠키 관련 헤더
- Set-Cookie : 서버에서 클라이언트로 쿠키 전달 (응답)
- Cookie : 클라이언트가 서버에서 받은 쿠키를 저장하고, HTTP 요청 시 서버로 전달
※ HTTP 쿠키의 핵심
: HTTP는 무상태(Stateless) 프로토콜
: 클라이언트와 서버가 요청과 응답을 주고받으면 연결이 끊어지며, 다시 요청할 경우 이전의 요청을 기억하지 못함



- Set-Cookie: sessionId=abc123; Expires=Sat, 27-Mar-2021 00:00:00 GMT; path=/; domain=.google.com; Secure
- 사용처 : 사용자 로그인 세션 관리 / 광고 정보 트래킹 (사용자가 보는 광고들 조회)
- 쿠키 정보는 항상 서버에 전송됨 → 네트워크 추가 트래픽을 유발하므로 최소한의 정보만 사용할 것
- 서버에 전송하지 않고 웹 브라우저 내부에 데이터를 저장하고 싶다면 웹 스토리지 참고할 것
- 주의! 보안에 민감한 데이터는 저장하면 안됨 (주민등록번호, 신용카드 번호 등)
1. 쿠키의 생명주기
- Set-Cookie: expires=Sat, 27-Mar-2021 00:00:00 GMT
- Set-Cookie: max-age=3600 (0이나 음수를 지정하면 쿠키 삭제)
- 세션 쿠키 : 만료 날짜를 생략하면 브라우저 종료 시 삭제
- 영속 쿠키 : 만료 날짜를 입력하면 해당 날짜까지 유지
2. 쿠키의 도메인
- 명시 : 명시한 문서 기준 도메인 + 서브 도메인
- 생략 : 하위 도메인에서는 쿠키를 접근할 수 없음
3. 쿠키의 경로
- 해당 경로를 포함한 하위 경로의 페이지만 쿠키 접근 가능
- 일반적으로 'path=/' 루트로 지정
4. 쿠키의 보안
- Secure : 원래 http와 https를 구분하지 않고 전송하지만 Secure 사용 시 https인 경우에만 전송
- HttpOnly : XSS 공격 방지 / 자바스크립트에서 접근 불가 / HTTP 전송에만 사용
- SameSite : XSRF 공격 방지 / 요청 도메인과 쿠키에 설정된 도메인이 같은 경우에만 쿠키 전송
▶ 캐시 관련 헤더
: 서버에서 응답을 줄 때 캐시 데이터는 'cache-control: max-age=60'과 같이 만료 시간을 보내줌
: 캐시 시간이 초과하고 데이터를 재사용할 때, 클라이언트의 데이터와 서버의 데이터가 같다는 사실 확인 필요

1. 검증 헤더
- 캐시 데이터와 서버 데이터가 같은지 검증하는 데이터
- Last-Modified, ETag
2. 조건부 요청 헤더
- 검증 헤더로 조건에 따른 분기
- If-Modified-Since, If-Unmodified-Since: Last-Modified 사용
- If-None-Match: ETag 사용
- 조건이 만족하면 200 OK / 조건이 만족하지 않으면 304 Not Modified
※ Last-Modified, If-Modified-Since 문제점
└> 1초 미만 단위로 캐시 조정 불가능
└> 데이터를 수정했지만, 다시 붙여넣은 식으로 데이터가 똑같은 경우
└> 서버에서 별도의 캐시 로직을 관리하고 싶은 경우
→ ETag, If-None-Match 방식으로 해결
└> ETag(Entity Tag)
└> 캐시용 데이터에 임의의 고유한 버전 이름을 달아둠
└> 데이터 변경 시 이 이름을 바꾸어서 변경 (Hash를 다시 생성)
└> ETag만 보내서 같으면 유지, 다르면 다시 받는 방식
└> 캐시 제어 로직을 서버에서 완전히 관리하는 방식
3. 캐시 제어 헤더
→ Cache-Control: 캐시 제어
└> Cache-Control: max-age - 캐시 유효 시간, 초 단위
└> Cache-Control: no-cache - 데이터는 캐시해도 되지만 항상 origin 서버에 검증하고 사용
└> Cache-Control: no-store - 데이터에 민감한 정보가 있으므로 저장하면 안됨
└> Cache-Control: must-revalidate - 캐시 만료 후 최초 조회 시 origin 서버에 검증해야 함,
- origin 서버 접근 실패시 반드시 504(Gateway Timeout) 오류가 발생해야 함
※ no-cache의 경우 must-revalidate와 다르게 origin 서버 접근 실패 시 이전 데이터를 보내줄 수 있음
→ Pragma: 캐시 제어 (하위 호환)
└> Pragma: no-cache
└> HTTP 1.0 하위 호환이라 거의 사용하지 않음
→ Expires: 캐시 유효 기간 (하위 호환)
└> expires: Mon, 01 Jan 1990 00:00:00 GMT
└> 캐시 만료일을 정확한 날짜로 지정
└> HTTP 1.0 부터 사용
└> 지금은 더 유연한 Cache-Control: max-age 권장
└> Cache-Control: max-age와 함께 사용 시 Expires는 무시
4. 프록시 캐시 관련 헤더

→ Cache-Control
└> Cache-Control: public - 응답이 public 캐시에 저장될 수 있음
└> Cache-Control: private - 응답이 해당 사용자만을 위한 것, private 캐시에 저장해야 함 (기본값)
└> Cache-Control: s-maxage - 프록시 캐시에만 적용되는 max-age
→ Age: 60 (HTTP 헤더) - origin 서버에서 응답 후 프록시 캐시 내에 머문 시간 (초)
※ 해당 페이지에 캐시를 완전히 차단하고 싶다면
→ Cache-Control: no-cache, no-store, must-revalidate
→ Pragma: no-cache
'Web > 기초 공부' 카테고리의 다른 글
| MVC 패턴 (0) | 2021.04.02 |
|---|---|
| 웹 애플리케이션 이해 (0) | 2021.03.29 |
| 웹 기본 (0) | 2021.03.26 |